NEO: The Evolution in Expressive, Full Talking Head Performance
NEO doesn't just lip-sync. It listens to how you speak and generates matching head movements, facial expressions, and eye gaze. The engine runs on latent diffusion and reinforcement learning.
A Quick Peek Inside NEO
Today, we are taking a closer look under the hood of NEO (Neural Expressive Output), our next-generation video engine designed to create incredibly realistic, full-talking-head performances.
Moving far beyond traditional lip-syncing, NEO understands the nuances of human speech to generate dynamic head movements, subtle facial cues, and lifelike eye expressions. By coupling state-of-the-art latent diffusion with reinforcement learning, NEO delivers an avatar experience that truly connects with viewers.
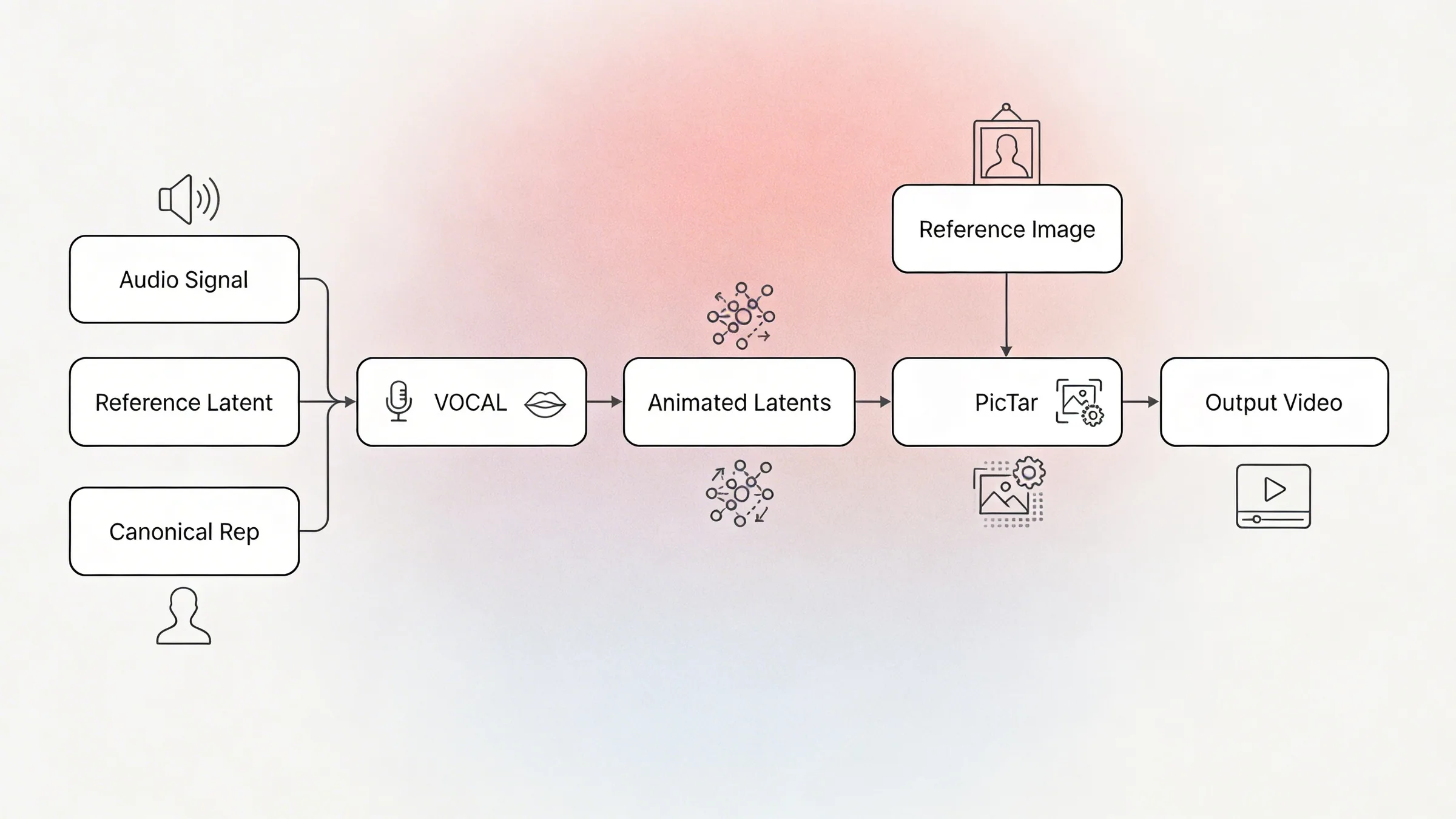
To synthesize these highly expressive performances, NEO is built from two tightly integrated core components:
- VOCAL (Voice-to-Latent): An advanced Audio-to-Latent model that listens to the input audio and generates the corresponding animated latents.
- Pictar (Rendering Model): A high-fidelity rendering model that takes the animated latents from VOCAL, along with a source image of a head, and brings the avatar to life.
The VOCAL Architecture
At the heart of NEO's audio-driven animation is VOCAL, powered by a Multi-Modal Diffusion Transformer (MMDiT). The same class of architecture behind some of the most advanced generative models in the world today.
Listening in HD
VOCAL doesn't just hear audio; it understands it at every level. A pretrained audio encoder processes the raw speech waveform and extracts deep acoustic features from all of its internal representation layers. These multi-scale features, capturing everything from low-level phonetics to high-level prosody and emotion, are fused together and projected into a rich conditioning signal that drives the entire animation.
Joint Attention: Where Audio Meets Motion
VOCAL's transformer blocks use Joint Attention; a mechanism where the audio signal and the motion latents attend to each other simultaneously through parallel processing streams.
Rather than treating audio as a secondary input bolted on via cross-attention, Joint Attention ensures that every nuance of the voice, a pause, a rising inflection, an emphatic stress, directly shapes the motion being generated, and vice versa. Both streams share information symmetrically, enabling a deeply intertwined understanding of speech and movement.
Adaptive Modulation
Each transformer block is further conditioned through adaptive shift-scale-gate modulation. The diffusion timestep and the speaker's structural identity features are encoded into per-layer modulation parameters that dynamically adjust the network's internal representations at every step of the denoising process. This ensures that the generated motion stays faithful to both the denoising schedule and the unique facial geometry of the speaker.
Guided Generation
At inference time, VOCAL leverages Classifier-Free Guidance (CFG) across multiple conditioning signals like audio, identity, and reference latent; allowing precise, tunable control over how strongly each factor influences the final performance. The result is a generation process that is both highly controllable and remarkably natural.
VOCAL Data Flow
Audio enters from the left, passes through four processing stages, and outputs animated latents that drive the video.
The Pictar Rendering Engine
Once VOCAL has produced expressive motion latents, it's Pictar's job to turn them into pixels you can't distinguish from a real video. Pictar operates in three stages:
Stage 1: 3D Lift
A single reference photograph of the speaker is projected into a high-dimensional 3D feature volume, a rich, volumetric representation that captures the geometry, texture, and lighting of the face from every angle. Think of it as building a detailed internal "3D sculpture" of the person from just one image.
Stage 2: Motion Deformation
The animated latents from VOCAL act as a set of motion instructions. At each frame, they warp and deform the 3D feature volume, rotating the head, raising an eyebrow, parting the lips, all while preserving the subject's identity. Because the deformation happens in 3D feature space rather than flat pixel space, the result is geometrically consistent, with no warping artifacts even during pose changes.
Stage 3: Photorealistic Translation
The deformed 3D features are then passed through a neural translation module that renders the final photorealistic frame. This module recovers fine-grained details, texture, and specular highlights, producing output that is virtually indistinguishable from a real camera feed.
By decoupling identity (the 3D feature volume) from motion (VOCAL's latents) and rendering (the translation network), Pictar can animate any enrolled identity with any performance, all while maintaining rock-solid visual consistency across thousands of frames.
Going Beyond Lip-Sync
Matching lip movements to audio is table stakes. For enterprise training and creator content, avatars need to act human. NEO hits state-of-the-art lip-sync accuracy and adds realistic head motion on top.
How did we achieve this level of realism? The foundation of NEO is built on thousands of hours of carefully curated, high-quality human performance data. But to truly push the boundaries of expressiveness and capture the elusive "human spark," we took it a step further.
We applied reinforcement learning on top of that foundation, teaching the model to respond to audio cues the way a real person would. When the audio rises in pitch or emphasis, the avatar nods or widens its eyes, getting closer to the natural feel of a real speaker.
Source to Output
See the 1:1 mapping between the driving performance and the generated avatar
Source Performance (Driving Video)
1:1 square. Raw webcam footage of a human speaker with natural head movements, expressions, and speech. Should include visible head turns, eyebrow raises, and varied emotions to demonstrate the range of motion being captured.NEO Output (Generated Avatar)
1:1 square. NEO-generated avatar replicating the exact same performance from the source video. Frame-synced with the input to show 1:1 motion fidelity. Same timing, same expressions, different face.Expression Range
The same avatar, six different emotional states
Neutral
16:9, 3-5s loop. Same avatar, neutral resting face. Subtle idle motion (micro blinks, slight breathing). No exaggerated expression.Happy
16:9, 3-5s loop. Same avatar smiling warmly. Visible cheek lift, eye crinkle, natural smile arc.Serious
16:9, 3-5s loop. Same avatar with a focused, serious expression. Slight brow furrow, direct eye contact.Surprised
16:9, 3-5s loop. Same avatar with widened eyes, raised brows, slightly open mouth. Surprise reaction.Explaining
16:9, 3-5s loop. Same avatar gesturing while speaking. Head tilts, hand motion if visible, teaching posture.Laughing
16:9, 3-5s loop. Same avatar genuinely laughing. Visible teeth, head tilt back, natural laugh movement.One Avatar, Any Language
The same character speaks natively in each language with matched lip movements
How NEO Compares
Benchmarked against leading open-source and commercial models
| Model | FID ↓ | LSE-D ↓ | LSE-C ↑ |
|---|---|---|---|
| NEO (Ours) | — | — | — |
| Open-Source Model A | — | — | — |
| Open-Source Model B | — | — | — |
| Open-Source Model C | — | — | — |
| Competitor 1 | — | — | — |
| Competitor 2 | — | — | — |
↓ = lower is better ↑ = higher is better. Values pending from research team.
The Challenge of Reinforcement Learning in Video
Fine-tuning language models with Reinforcement Learning (RL) has become standard practice, but applying RL to continuous, diffusion-based video models is a monumental engineering challenge.
Unlike text, where an RL algorithm can easily score discrete words, continuous models map infinite mathematical trajectories. Tracking the "probabilities" of these continuous motions during training normally requires an impossible amount of GPU memory and faces severe instability. Furthermore, naive RL often leads to "reward hacking," where the avatar might learn bizarre, unnatural twitches just to mathematically satisfy the reward function.
Kinetic-GRPO
While some attempts at applying GRPO to flow models exist, they often rely on computationally heavy, idealized mathematical conversions. For example, recent proposals compute Kullback-Leibler (KL) divergence by continuously calculating the massive difference between velocity fields at every single step. For high-fidelity video generation like ours, evaluating these massive velocity fields at every frame is too slow and computationally prohibitive.
To solve this, we developed Kinetic-GRPO (Group Relative Policy Optimization), tailored specifically for our high-resolution MMDiT architecture. Rather than attempting to backpropagate through an entire generation timeline at once, or calculating punishing velocity-field differences, we decoupled the training process:
Group Scoring
The model generates a group of diverse candidate performances for the same audio clip. A specialized Transformer Reward Model evaluates these candidates, identifying which subtle movements look the most natural and aesthetically pleasing.
Memory-Efficient SDE Replay
We 'replay' the generation steps using a stochastic differential equation (SDE) formulation. By isolating the exact noise injected at each step, we can calculate the probabilities of the generated motion directly from the noise distribution itself, sidestepping the need for continuous, heavy velocity-field divergence tracking.
Algorithmic Anchoring (KL Penalty)
To completely prevent reward hacking, we implement an algorithmic safety net. But instead of penalizing the velocity network (which is slow), Kinetic-GRPO efficiently calculates the KL penalty based simply on the mean positional difference between the current model and the reference model at each step. This rigorously anchors the model to its highly realistic base state without bogging down training speed.
The result is a model that learns the subtle micro-expressions that make an avatar feel genuinely alive, optimized directly for the high-quality visual output.
Before and After Kinetic-GRPO
Same model, same audio input. Reinforcement learning shifts every quality dimension.
Base diffusion model without Kinetic-GRPO fine-tuning
Same model after Kinetic-GRPO reinforcement learning fine-tuning
How Kinetic-GRPO Works
Generate Candidates
The model produces a group of candidate avatar performances from the same audio clip. Each candidate has slightly different head motion, expressions, and timing.
Score with Reward Model
A specialized Transformer Reward Model evaluates each candidate and assigns quality scores based on naturalness, expression range, and audio alignment.
SDE Replay Gradients
Memory-efficient SDE replay reconstructs the diffusion path and computes gradients without storing intermediate states. This makes RL training possible at high resolution.
KL Penalty Anchoring
A KL divergence penalty anchors the model to its base behavior, preventing reward hacking. The model improves expressiveness without losing realism.
Built on Responsible AI Governance
With highly realistic avatar technology comes a deep responsibility to ensure it is used safely and ethically. At the core of NEO's development are strict AI governance principles.
Consent is mandatory
We have built-in safeguards that make it impossible to create an avatar without explicit, verifiable consent from the individual.
Protection of public figures
Our systems actively block the creation of avatars depicting famous people or politicians.
Age restrictions
We enforce strict age verification to prevent the misuse of minors' likenesses.
We are committed to empowering creators and enterprises to build engaging, instructional, and entertaining content at scale, while relentlessly protecting individual identity.
Frequently asked questions
What is NEO?
NEO (Neural Expressive Output) is Colossyan's video engine for generating full talking-head performances from audio input. It combines two models: VOCAL, which converts speech into animated latent codes, and Pictar, which renders those codes into photorealistic video frames. NEO produces natural head movements, facial expressions, and eye gaze, not just lip-sync.
How does NEO differ from traditional lip-sync models?
Traditional lip-sync models map audio to mouth shapes. NEO generates the full performance: head pose, eyebrow raises, blinks, gaze direction, and lip movements together. It uses a diffusion-based architecture trained on thousands of hours of human performance data, then fine-tuned with reinforcement learning (Kinetic-GRPO) to improve expressiveness.
What is VOCAL and how does it work?
VOCAL (Voice-to-Latent) is the audio-to-motion component of NEO. It uses a Multi-Modal Diffusion Transformer (MMDiT) that processes speech through a pretrained audio encoder, extracts multi-scale acoustic features (phonetics, prosody, emotion), and generates animated latent codes through joint attention between audio and motion streams.
What is Pictar?
Pictar is the rendering engine in NEO. It takes VOCAL's motion latents plus a single reference photo and produces photorealistic video. It works in three stages: 3D Lift (photo to 3D feature volume), Motion Deformation (latents warp the volume each frame), and Photorealistic Translation (neural rendering of the final output).
What is Kinetic-GRPO?
Kinetic-GRPO (Group Relative Policy Optimization) is a reinforcement learning method we built for training diffusion-based video models. It generates groups of candidate performances, scores them with a Transformer Reward Model, and uses memory-efficient SDE replay to compute gradients. A KL penalty prevents reward hacking by anchoring the model to its base behavior.
How fast is NEO?
NEO runs at 60+ fps with sub-20ms inference latency. It uses optimized compute kernels and dynamic ROI allocation, spending more resources on expressive face regions (eyes, mouth) and less on static areas.
Does NEO require a lot of source material?
No. NEO can create a new avatar performance from as little as 3.5 seconds of reference footage. A single photograph is enough for Pictar to build its 3D feature volume of the speaker's face.
How does Colossyan handle ethics and consent for AI avatars?
Colossyan requires explicit consent before creating any avatar. Public figure likenesses are protected, and age restrictions are enforced. These are hard guardrails built into the platform, not optional settings.
Related Research

NEO 2: AI Dubbing and Lip Sync
Cross-lingual lip-sync that maps phonemes onto facial movements in a single forward pass. Photorealistic dubbing across 30+ languages.

Sign Language AI Generation
Generating sign language directly from text and speech. No human signer required. A new approach to making video content accessible at scale.

Multi-Person AI Scenarios
Real-time multi-avatar scenes for training simulations. Multiple AI characters interacting naturally in a single video frame.